
作者:Gunar Lorenz博士 英飞凌科技技术市场高级总监
校对:丁越 英飞凌科技消费、计算与通讯业务大中华区 首席工程师
导言
在英飞凌,我们一直坚信卓越的音频解决方案对于提升消费类设备的用户体验至关重要。我们坚定不移地致力于创新,在主动降噪、语音透传、录音室录音、音频变焦和其他相关技术方面取得了显著进步,对此我们深感自豪。作为MEMS麦克风的领先供应商,英飞凌集中资源改善MEMS麦克风的音频质量,为TWS和耳罩式耳机、笔记本电脑、平板电脑、会议系统、智能手机、智能音箱、助听器甚至汽车等各种消费设备带来卓越体验。
今天,我们生活在一个激动人心的时代,人工智能正在彻底改变日常生活,而ChatGPT等工具正在通过直观的文本和语音交互重新定义工作效率。随着人工智能系统的不断进步,传统的商业模式、信仰和假设正在受到挑战。语音在新兴的人工智能生态系统中扮演什么角色?作为企业领导者,我们是否需要重新思考我们的信念? 生成式人工智能的兴起是否会降低高质量语音输入的重要性,或者高质量语音输入是否会成为广泛采用人工智能服务和个人助理的必要条件?
人工智能,从得力助手到最好的朋友
人类不仅会根据问题的内容,也会根据提问的形式调整自己的回答,这是很自然的事情。人类的声音提供了各种线索,可用来判断提问者的年龄、性别、社会和文化背景以及情绪状态。此外,识别所处的环境(如机场、办公室、交通或跑步等体育活动)也有助于确定提问者的意图,并相应地调整答案并更好的对话。
尽管人工智能的能力有了长足的进步,但人们仍然认为,基于人工智能的辅助工具缺乏正确预测人类提问意图或特定信息将如何被解读的能力。为了改善人机交互,人工智能在做出修辞选择时应考虑三个关键因素:对听者的了解、听者的情绪状态和环境背景。
在许多情况下,仅凭接收到的音频信号就足以提取有用的信息并做出适当的反应。例如,考虑一下与素未谋面的人进行电话或音频会议的情况。更重要的是,考虑一下在没有机会当面交流的情况下,一个人在反复交谈后对另一个人的感知是如何发展和变化的。
最近的研究表明,即使人工智能的语言反应风格发生微小的变化,也会导致人工智能的社交能力和个性发生明显变化。我们有理由假设,在适当的声音输入水平下,未来的人工智能系统将能够作为有效的伙伴发挥作用,表现出人类朋友的行为,例如询问并真正倾听答案,或者只是倾听并在适当的时候保留判断。
人类如何体验音频信号?
与任何语言交流一样,音频信息也使用语言和文字来传达思想、情感和观点。此外,音调、速度、音量和背景噪音等其他交流元素也会影响对信息的整体感知。
从科学的角度来看,人耳基于两个关键因素来感知音频信号:频率和声压级。声压级(SPL)以分贝(dBSPL)为单位,表示围绕环境大气压振荡的声压幅度。100dBSPL的声压级相当于割草机或直升机发出的巨大噪音。声压级范围内的最低点(0dB)等效于20µPa的声压振荡,这代表具有最佳听力的健康年轻人在1kHz频率下的听力阈值。所有与语言有关的人类声音都属于100Hz至8kHz的频段。根据ISO 226:2023 标准,相应的人类听力阈值如图1所示。
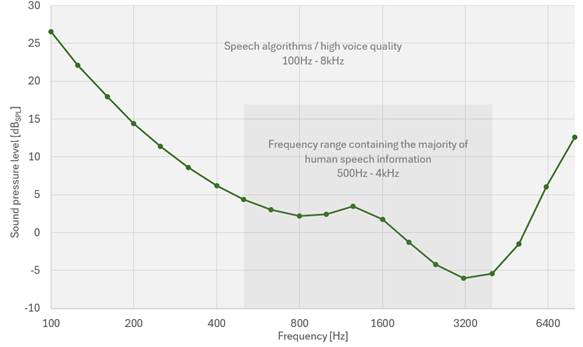
我们大多数人都知道,人类的听力阈值会随着年龄的增长而下降,如图 2 所示。
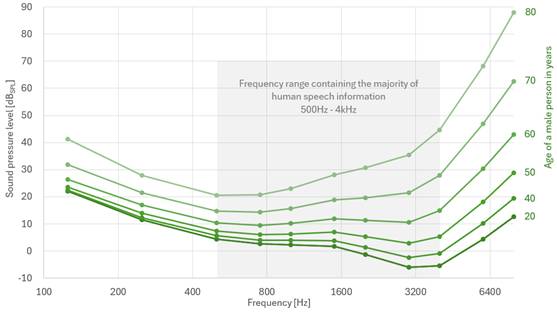
目前的音频硬件是否足以满足未来人工智能的需要?
既然我们已经对人类如何感知音频信号有了更好的了解,那么让我们重新审视一下最初的问题,即当前和未来的人工智能需要什么样的音频输入质量,才能达到与人类无异的水平。
目前市场上的大多数消费类设备都使用MEMS麦克风记录音频信号。MEMS 麦克风是人工智能个人助理的主要音频捕捉技术,使用人工智能助理技术的设备目前已开始在市场上销售。
MEMS 麦克风的录音质量取决于其动态范围(dynamic range)。动态范围的上限由声学过载点 (AOP) 确定,它定义了麦克风在高声压级时的失真性能。麦克风的自噪声确定了其动态范围的下限。衡量麦克风自噪声的方法是信噪比(SNR),它定义了麦克风的自噪声与其捕获的信号(灵敏度)之间的比率。不过,就我们的讨论而言,信噪比有些不合适,因为信噪比的自噪声使用了A计权(A-weighting),而A计权其实是基于人类感知音频信号的能力来定义的。
如果音频信号的预期接收者是人工智能,则相关的麦克风的等效噪声级ENL(equivalent noise level)是衡量性能的更合适参数,因为它忽略了录制声音的人类感知因素。等效噪声级ENL指的是在没有外部声源的情况下麦克风产生的信号。等效噪声级ENL以分贝(dBSPL)为单位,表示与麦克风自噪声相同电压的声压级。
值得注意的是,无论后期采用何种声音处理方法,低于等效噪声级ENL的任何声音信息基本上都会丢失,无法恢复。因此,如果音频链路中没有其他元件在信号到达人工智能算法之前引入噪音,麦克风ENL就可以被视为人工智能算法的听觉阈值。应该注意的是,这是一个高度简化的假设,因为音频链中通常还有许多其他组件,包括声道、防水保护膜和音频处理链路。
请参考图 3两种MEMS麦克风等效噪声级ENL曲线与人类听力阈值的直观对比。
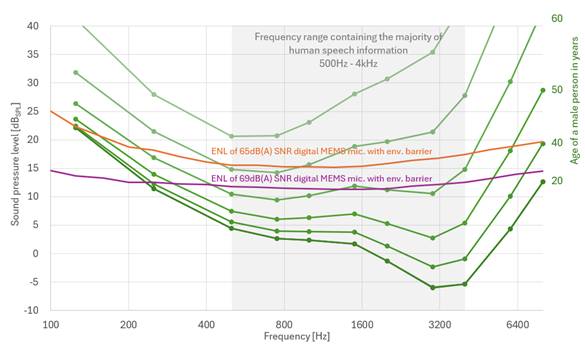
下面的紫色线条表示英飞凌最新高端数字麦克风的等效噪声级ENL曲线,该麦克风具有创新的防护设计,可实现防尘防水效果。这款麦克风代表了当前的技术水平,今年才在高端平板电脑上发布。我们预计,到今年年底,性能相当的麦克风将出现在高端智能手机上。值得注意的是,将麦克风的自噪声降低 5-10dB是一项重大成就,特别是考虑到声压是使用对数刻度来表示的。
虽然英飞凌在降低高端MEMS麦克风的自噪声方面取得了显著进展,但与人耳相比,麦克风在辨别低声压级的能力方面仍有很大差距。尤其是2kHz附近,对于确保人类听众获得高水平的声音清晰度至关重要。年轻人的听觉能力与英飞凌最先进的麦克风之间的差距超过12dBSPL。与目前高端手机中使用的麦克风相比,差距明显更大,达到17dBSPL。需要再次指出的是,这一评估仅考虑了MEMS麦克风的自噪声,并未考虑音频链中会进一步降低整体性能的额外噪声源。
目前MEMS麦克风技术的局限性在包含大部分人类语音信息的频率范围(500Hz - 4kHz)内最为明显。即使是市场上最先进的MEMS麦克风,其声音理解能力也只能达到60岁老人的水平。根据现有数据,可以合理地预计,使用最新MEMS麦克风技术的人工智能虚拟助手将出现与老年人类似的听力障碍,特别是在需要在嘈杂环境中或远距离跟读对话的情况下。
总结与展望
人工智能的飞速发展不仅不会减缓,反而会加速MEMS麦克风向更高信噪比发展的趋势。虽然最新的MEMS麦克风还无法与人耳的音频质量相媲美,但英飞凌在降低麦克风自噪声方面取得的进展有利于现有和未来的人工智能。进一步改进音频链路将是增强人工智能能力的关键,例如周围环境分辨、语境理解、情感意识、说话者识别和多人对话记录。有了更好的音频输入,人工智能与人类的互动方式将能与人类之间的互动相匹配,甚至不相上下。
此外,人机交互水平的提高将促成新的基于人工智能的用例和服务。例如,想象一下未来的微软Copilot,它不仅能总结团队会议内容,还能提供对交谈氛围的整体评估。未来的人工智能辅助功能或许可以基于人类的语音和音频,突出显示重点或按照重要性进行排序。此外,还可以添加辅导功能,为用户提供有用的建议,帮助他们更好地将未来的对话引向所需的方向。
试想一下,人工智能可以对新的求职者进行第一轮面试,或者仅凭音频就能识别说话者,其安全级别足以满足网上购物的需要。
所有这些可能只是未来人工智能的一小部分,未来人工智能的听力能力将达到或超过人类。凭借我们的增强型 MEMS麦克风解决方案,英飞凌很荣幸能够参与这一激动人心的旅程。
免责声明: 本文章转自其它平台,并不代表本站观点及立场。若有侵权或异议,请联系我们删除。谢谢! Disclaimer: This article is reproduced from other platforms and does not represent the views or positions of this website. If there is any infringement or objection, please contact us to delete it. thank you! |
- 上一篇:一文看懂电压转换的级联和混合概念
- 下一篇:LCR数字电桥来测量电容和电感的详细步骤

关注矽源特公众号

矽源特微信客服
 发送邮件
发送邮件 商务QQ客服
商务QQ客服 13823761625
13823761625
